
The full-stack NVIDIA accelerated computing platform has once again demonstrated exceptional performance in the latest MLPerf Training v4.0 benchmarks.
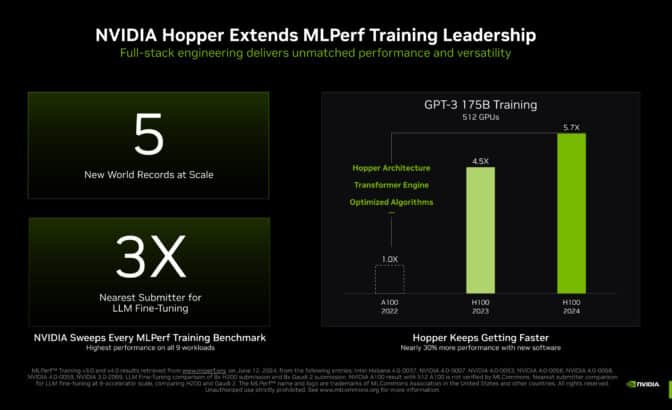
NVIDIA more than tripled the performance on the large language model (LLM) benchmark, based on GPT-3 175B, compared to the record-setting NVIDIA submission made last year. Using an AI supercomputer featuring 11,616 NVIDIA H100 Tensor Core GPUs connected with NVIDIA Quantum-2 InfiniBand networking, NVIDIA achieved this remarkable feat through larger scale — more than triple that of the 3,584 H100 GPU submission a year ago — and extensive full-stack engineering.
Thanks to the scalability of the NVIDIA AI platform, Eos can now train massive AI models like GPT-3 175B even faster, and this great AI performance translates into significant business opportunities. For example, in NVIDIA’s recent earnings call, we described how LLM service providers can turn a single dollar invested into seven dollars in just four years running the Llama 3 70B model on NVIDIA HGX H200 servers. This return assumes an LLM service provider serving Llama 3 70B at $0.60/M tokens, with an HGX H200 server throughput of 24,000 tokens/second.
NVIDIA H200 GPU Supercharges Generative AI and HPC
The NVIDIA H200 Tensor GPU builds upon the strength of the Hopper architecture, with 141GB of HBM3 memory and over 40% more memory bandwidth compared to the H100 GPU. Pushing the boundaries of what’s possible in AI training, the NVIDIA H200 Tensor Core GPU extended the H100’s performance by up to 47% in its MLPerf Training debut.
NVIDIA Software Drives Unmatched Performance Gains
Additionally, our submissions using a 512 H100 GPU configuration are now up to 27% faster compared to just one year ago due to numerous optimizations to the NVIDIA software stack. This improvement highlights how continuous software enhancements can significantly boost performance, even with the same hardware.
This work also delivered nearly perfect scaling. As the number of GPUs increased by 3.2x — going from 3,584 H100 GPUs last year to 11,616 H100 GPUs with this submission — so did the delivered performance.
Learn more about these optimizations on the NVIDIA Technical Blog.
Excelling at LLM Fine-Tuning
As enterprises seek to customize pretrained large language models, LLM fine-tuning is becoming a key industry workload. MLPerf introduced a new LLM fine-tuning benchmark this round, based on the popular low-rank adaptation (LoRA) technique applied to Meta Llama 2 70B.
The NVIDIA platform excelled at this task, scaling from eight to 1,024 GPUs, with the largest-scale NVIDIA submission completing the benchmark in a record 1.5 minutes.
Accelerating Stable Diffusion and GNN Training
NVIDIA also accelerated Stable Diffusion v2 training performance by up to 80% at the same system scales submitted last round. These advances reflect numerous enhancements to the NVIDIA software stack, showcasing how software and hardware improvements go hand-in-hand to deliver top-tier performance.
On the new graph neural network (GNN) test based on R-GAT, the NVIDIA platform with H100 GPUs excelled at both small and large scales. The H200 delivered a 47% boost on single-node GNN training compared to the H100. This showcases the powerful performance and high efficiency of NVIDIA GPUs, which make them ideal for a wide range of AI applications.
Broad Ecosystem Support
Reflecting the breadth of the NVIDIA AI ecosystem, 10 NVIDIA partners submitted results, including ASUS, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, Oracle, Quanta Cloud Technology, Supermicro and Sustainable Metal Cloud. This broad participation, and their own impressive benchmark results, underscores the widespread adoption and trust in NVIDIA’s AI platform across the industry.
MLCommons’ ongoing work to bring benchmarking best practices to AI computing is vital. By enabling peer-reviewed comparisons of AI and HPC platforms, and keeping pace with the rapid changes that characterize AI computing, MLCommons provides companies everywhere with crucial data that can help guide important purchasing decisions.
And with the NVIDIA Blackwell platform, next-level AI performance on trillion-parameter generative AI models for both training and inference is coming soon.

